所屬科目:教甄◆資訊科技概論專業(電腦科)
1. 將中序表示式 (A + B) * C 轉換成後序表示式(Postfix)後,結果為何? (A) AB+C* (B) ABC*+ (C) *+ABC (D) AB*C+
2. 有一個長度為 8 的已排序陣列,使用二元搜尋尋找特定數值,最多需要幾 次比較? (A) 3 次 (B) 4 次 (C) 7 次 (D) 8 次
3. 下列哪種排序演算法的基本思想是透過不斷交換相鄰的元素,將最大值移向 一端? (A) 合併排序 (B) 快速排序 (C) 泡沫排序 (D) 選擇排序
4. 二元搜尋(Binary Search)演算法的前提條件是資料必須具備什麼特性? (A) 已排序 (B) 為整數 (C) 儲存於鏈結串列 (D) 資料量小於 100
5. 在 C 語言函式呼叫中,若傳入的是變數的位址(如 func(&x)),這屬於哪 種傳遞方式? (A) Call by Value (B) Call by Reference (C) Call by Name (D) Call by ID
6. Python 程式碼 print(3 * [1, 2]) 的輸出結果為何? (A) [3, 6] (B) [1, 2, 1, 2, 1, 2] (C) [1, 2, 3] (D) 錯誤(Error)
7. 在 C/C++ 中,宣告一個可以儲存小數的變數應使用哪個關鍵字? (A) int (B) char (C) float (D) bool
8. 關於布林邏輯,A AND (NOT A) 的結果恆為何? (A) 真 (B) 假 (C) A (D) NOT A
9. 在色彩表示法 RGB (8,8,8) 中,總共可以產生多少種顏色組合? (A) 256 (B) 65536 (C) 16777216 (D) 2⁴
10. 虛擬化技術(Virtualization)中,管理多個虛擬機器的軟體層稱為何? (A) Kernel (B) Hypervisor (C) BIOS (D) Driver
11. 下列何者屬於「監督式學習(Supervised Learning)」的特徵? (A) 資料不需要標籤 (B) 透過與環境互動獲得獎勵 (C) 資料需有成對的輸入與正確標籤 (D) 自動發現資料的隱藏結構
12. 根據《中小學使用生成式人工智慧注意事項》,學生使用 AI 產出作業時應 注意? (A) 只要標註來源即可全文複製 (B) 需具備批判思考並進行事實查證 (C) 應盡量使用 AI 破解軟體限制 (D) AI 答案恆為正確不必懷疑
13. 深度學習神經網路中,「反向傳播(Backpropagation)」的主要目的是? (A) 初始化權重 (B) 計算誤差梯度並更新權重 (C) 增加網路層數 (D) 壓縮資料量
14. 電腦教室管理中,若要實現「網路開機(Wake-on-LAN)」,通常需透過發送 什麼封包? (A) DNS Request (B) Magic Packet (C) Ping (D) Token
15. 關於非對稱式加密(如 RSA),下列敘述何者正確? (A) 加密與解密使用相同金鑰 (B) 公鑰可以向大眾公開 (C) 私鑰必須與公鑰一起公佈在網站上 (D) 加密速度通常比對稱式快
16. 電腦教室使用 PXE (Preboot eXecution Environment) 進行系統還原時,主要 依賴哪兩種服務? (A) DHCP & TFTP (B) HTTP & FTP (C) DNS & SMTP (D) SSH & TELNET
17. 下列關於 HTTPS 的敘述何者錯誤? (A) 使用 443 通訊埠 (B) 採用 SSL/TLS 加密 (C) 僅能保護伺服器端不被攻擊 (D) 提供資料完整性驗證
18. 某學生要設計一套班級成績分析系統。在開始撰寫程式之前,他先分析真實 情境中的資料與關係,將「學生」、「科目」、「成績」與「班級」整理成 以下結構: 一位學生可以有多筆不同科目的成績。 一個班級包含多位學生。 每筆成績需記錄科目名稱與分數。 學生接著畫出資料表關係圖,規劃各資料欄位與資料之間的關聯,再據此設 計程式。關於此作法,下列何者正確? (A) 此作法主要屬於模組化程式設計(modular programming),因為學生把 系統拆成「學生」、「科目」、「成績」與「班級」等部分,並可提升 程式可維護性。 (B) 此作法主要屬於建模(modeling),因為學生將真實世界中的班級成績 情境抽象化為資料、關係與規則。 (C) 此作法主要屬於物件導向程式設計(object-oriented programming),因 為只要找出系統中的實體名稱,就等同於完成類別與物件的設計。 (D) 此作法主要屬於資料庫正規化(database normalization),因為學生已經 將所有資料關係整理成有效的資料表結構。
19. 一座工廠有四條生產線 A、B、C、D,每天固定啟動一條生產線,但同一 條生產線不能連續兩天運作。已知 ?????[?][?]表示第 i 天啟動第 j 條生產 線時可獲得的產值,其中 j 可為 A、B、C、D。若以 ??[?][?] 表示「第 ? 天啟動第 ? 條生產線時,從第 1 天到第 ? 天可得到的最高總產值」,下列 哪一個遞迴關係式(recurrence relation)最適合用來計算 ??[?][?]? (A) ??[?][?] = ?????[?][?] + max ?≠? ??[? − 1][?] (B) ??[?][?] = ?????[?][?] + max ?≠? ??[?][?] (C) ??[?][?] = ?????[?][?] + max ?≠? ??[? − 2][?] (D) ??[?][?] = max ?≠? (?????[?][?] + ??[? − 1][?])
20. 某學校的工程師在一台辦公室電腦上測試校內教學平台連線,結果如下: ping 203.64.12.10 → 成功 ping course.school.edu.tw → 失敗,顯示「找不到主機名稱」 將 DNS 伺服器改為另一組公共 DNS 後,再次執行: ping course.school.edu.tw → 仍然失敗,顯示「找不到主機名稱」 在該電腦的 hosts 檔案中加入: 203.64.12.10 course.school.edu.tw 再次執行: ping course.school.edu.tw → 成功 根據以上測試結果,最可能的問題原因為何? (A) 防火牆封鎖了對外的 HTTPS 流量。 (B) 本機或網路環境中的 DNS 查詢流程異常,導致主機名稱無法被解析。 (C) 路由器的 NAT 設定錯誤,導致封包無法轉送至外部網路。 (D) 網路卡驅動程式損毀,導致封包無法正常送出。
21. 給定無向圖如下: 此圖的最小生成樹(Minimum Spanning Tree)權重總和為何? (A) 6 (B) 8 (C) 10 (D) 12
22. 使用 K-means 演算法進行分群。若有 6 筆資料如下:P1 = (2, 1) P2 = (7, 7) P3 = (3, 1) P4 = (1, 4) P5 = (6, 9) P6 = (11, 8) 欲將資料分成 2 群,初始群心設定為: C1 = (1, 1) C2 = (8, 8)
若使用歐氏距離(Euclidean distance)進行分群,請問經過第一次分群指派 並重新計算群心後,新的群心座標為何? (A) C1 = (1, 1),C2 = (8, 8) (B) C1 = (2, 2),C2 = (8, 8) (C) C1 = (13/4, 13/4),C2 = (17/2, 17/2) (D) C1 = (13/3, 10/3),C2 = (26/3, 20/3)
23. 下圖為一個簡化的檔案樹狀結構,共有 A~L 12 個資料夾。 若從資料夾 A 開始進行深度優先搜尋(Depth-First Search, DFS),並且同 一層資料夾必須依英文字母順序由小到大拜訪,請問下列何者為正確的拜訪順序? (A) A→B→E→F→I→J→C→G→K→L→D→H (B) A→B→E→I→F→J→C→G→K→L→D→H (C) A→B→C→D→E→F→G→H→I→J→K→L (D) I→J→K→L→E→F→G→H→B→C→D→A
24. 某主機 IP 位址為 172.16.20.130,子網路遮罩為 255.255.255.192。下列哪 一個 IP 與該主機位於同一子網路? (A) 172.16.20.63 (B) 172.16.20.100 (C) 172.16.20.150 (D) 172.16.20.200
25. 下列關於網路攻擊名稱與主要手法的配對,何者正確? (A) Phishing:利用大量流量癱瘓目標伺服器,使其無法提供服務 (B) DDoS:偽造官方網站或郵件,引誘使用者輸入帳號密碼 (C) SQL Injection:將惡意 SQL 指令插入輸入欄位,以嘗試讀取、竄改或 破壞資料庫 (D) Social Engineering:利用程式自動排序大量資料,以提升系統效能
26. 進行聲音數位化時,通常會經過取樣(sampling)與量化(quantization)。 關於取樣與量化的敘述,下列何者最正確? (A) 取樣頻率主要影響時間軸上的解析度,量化位元數主要影響振幅可被 示的精細程度。 (B) 提高量化位元數可以增加每秒取樣的次數,因此主要影響高頻聲音是否 能被正確記錄。 (C) 提高取樣頻率可以增加每次取樣時可表示的音量層次,因此主要可降低 聲音雜訊。 (D) 只要量化位元數足夠高,即使取樣頻率很低,也能完整還原原始聲音中 的高頻成分。
27. 某校資訊教師帶領學生製作一個影像辨識模型,用來判斷校園植物照片屬於 「樺樹、榕樹、白千層」三種類別之一。學生蒐集了 500 張訓練影像,其 中大多數照片都在晴天、正面角度、背景單純的情況下拍攝。模型在訓練資 料上的準確率達 98%。但後續新拍攝的照片辨識率不佳,尤其遇到陰天、 側面角度或背景複雜的照片時容易判斷錯誤。關於此情況,下列敘述何者最 合理? (A) 模型在新照片表現不佳,主要是因為訓練 epochs 不夠多。 (B) 若模型在新照片表現不佳,最適合直接增加輸出類別數量,讓模型可以 辨識更多植物種類,以改善原本三類植物的辨識效果。 (C) 影像辨識模型的設計原本就是設定只能辨識與訓練資料完全相同的照 片,因此只要新照片與訓練照片不同,辨識錯誤是必然現象。 (D) 模型可能過度擬合訓練資料中的拍攝條件與背景特徵,可透過增加多樣 化資料來提升模型的泛化能力。
28. 關於多因素驗證(multi-factor authentication, MFA)的敘述,下列何者正 確? (A) MFA 常見的做法是透過兩個步驟的登入流程,例如先輸入密碼再回答預 先設定的安全性問題。 (B) MFA 要求使用者依序通過多個驗證步驟,因此只要增加驗證步驟的數 量,安全強度就能獲得線性提升。 (C) MFA 的重點在於結合不同類型的驗證因素,例如密碼搭配一次性驗證 碼、硬體安全金鑰或生物特徵。 (D) MFA 主要用來加密使用者資料,因此可避免資料庫遭 SQL injection 攻 擊。
29. 若使用選擇排序(selection sort)欲將下列陣列由小到大排序: [24, 17, 9, 31, 13] 每一輪會找出目前尚未排序元素的最小值,請問執行完第 2 輪後,陣列狀態 為何? (A) [9, 13, 24, 31, 17] (B) [9, 17, 24, 31, 13] (C) [9, 13, 17, 24, 31] (D) [13, 17, 9, 31, 24]
30. 當大型語言模型讀到一個句子: 「學生把作業交給老師,因為他明天要請假。」 要產生回答或進行語意分析時,模型需要根據上下文判斷「他」較有可能指 的對象是老師還是學生。若模型使用 Transformer 架構,下列哪一個機制最 能幫助模型在處理「他」這個 token 時,同時參考句中其他 token 的語意 關聯? (A) 使用位置編碼(positional encoding)記錄每個 token 在句子中的位置, 以判定代名詞所指涉的對象。 (B) 使用詞嵌入(word embedding)將每個 token 轉換成向量,便可確認每 個 token 的語意。 (C) 使用前饋神經網路(feed-forward neural network)調整「他」這個 token 的向量表示,使其包含更多語意資訊,進而判斷所指對象。 (D) 使用自注意力機制(self-attention)計算 token 之間的關聯權重,使模 型可依上下文調整各 token 的表示。
31. 某教師想將一本市售參考書的整章內容輸入生成式 AI,請 AI 改寫成較口語 化的講義,再將改寫後的講義整理成自己的教材並上傳販售。關於此作法, 下列何者最合理? (A) 只要經過 AI 改寫,就會自動成為全新的著作,不必再考慮智財權的問 題。 (B) 因為 AI 不是人,所以 AI 改寫出的內容並不會構成侵權。 (C) 將他人著作輸入 AI 進行改寫並公開販售,可能涉及重製、改作或侵權 風險,應注意授權與合理使用範圍。 (D) 因為是由生成式 AI 工具修改,所以著作權責任應由 AI 平台的廠商承 擔,使用者不需注意授權問題。
32. 李老師從某官方網站下載教學軟體安裝檔 setup.exe。下載頁面另列出該檔案 的 SHA-256 雜湊值(hash value),並提供對應的數位簽章檔 setup.exe.sig。 關於 SHA-256 雜湊值與數位簽章的用途,下列何者錯誤? (A) 使用者可在本機計算 setup.exe 的 SHA-256 雜湊值,並與官方網站公佈 的雜湊值比對,以確認檔案內容是否一致。 (B) 若使用者在本機計算出的 SHA-256 雜湊值與官方公佈值不同,表示下 載檔案與官方公布版本內容不一致。 (C) 數位簽章可協助驗證檔案是否由可信發佈者簽署,並確認簽署後檔案是 否被竄改。 (D) 若 SHA-256 雜湊值比對一致,即可確認該檔案是由官方發佈。
33. 某程式如下: void A(int x) { cout << "A" << x; } void B(int x) { cout << "b" << x; A(x + 1); cout << "B" << x; } int main() { B(2); cout << "E"; return 0; } 程式執行後輸出為何? (A) b2B2A3E (B) b2A3B2E (C) A3b2B2E (D) b2A3EB2
34. 以下 Python 遞迴函式執行後,輸出為何? def f(n): if n <= 1: return 1 return n * f(n - 2) print(f(6)) (A) 12 (B) 24 (C) 48 (D) 720
35. 以下 HTML 與 JavaScript 程式會修改超連結內容,網頁最後顯示的超連結 文字與連結目標為何? (A) 顯示「舊網站」,連到 https://old.example.com (B) 顯示「前往學校網站」,連到 https://old.example.com (C) 顯示「舊網站」,連到 https://www.example.edu.tw (D) 顯示「前往學校網站」,連到 https://www.example.edu.tw
36. 以下 Linux 指令的主要作用為何? chmod +x run.sh (A) 刪除 run.sh (B) 讓 run.sh 可執行 (C) 壓縮 run.sh (D) 顯示 run.sh 內容
37. 某資訊科技教師想在上課簡報中使用網路上的圖片,圖片標示授權為 `CC BY-NC-SA 4.0`,下列哪一項使用方式最符合此授權條件? (A) 可以自由使用,不需要標示作者,也可以改作後販售 (B) 可以在教學簡報中使用,但需標示作者;若改作後分享,也應採相同或 相容授權,且不得作商業使用 (C) 只要是學校使用,就可以刪除作者姓名並改成自己的作品 (D) 只能觀看,不能下載、引用、改作或放入簡報
38. 使用 AI 進行 vibe coding 時,若採用 SDD(Spec-Driven Development)觀 念,下列哪一項做法最符合 SDD 精神? (A) 先讓 AI 自由生成完整系統,再依照畫面感覺慢慢修改 (B) 先撰寫明確需求、介面規格與驗收條件,再讓 AI 依規格產生程式與測 試 (C) 只要 AI 產生的程式能執行,就不需要測試或文件 (D) 將所有需求用一句「幫我做一個好用的網站」交給 AI 自行判斷
39. 下圖是一張 4×4 影像,每格數字代表一個像素的灰階值,共有 4 種灰階 (0、1、2、3)。若不考慮壓縮,至少需要多少位元才能完整表示這張圖? 0 1 2 31 1 0 23 2 2 1 0 0 1 3 (A) 16 位元 (B) 24 位元 (C) 32 位元 (D) 64 位元
40. 觀察下列網路架構圖,下列哪一個裝置最主要負責把學校區域網路的資料送往外部網際網路? (A) Switch (B) Router (C) Printer (D) Browser
41. 下圖為「垃圾分類影像辨識」專題的監督式學習流程。若要提升模型品質,同時維持評估的公正性,下列做法何者最適當? (A) 增加多樣且正確標註的訓練資料,並保留獨立測試資料只用於最後評估 (B) 將測試資料加入訓練資料中,讓模型看過更多圖片後再回報測試準確率 (C) 只針對測試資料表現反覆調整模型參數,直到測試準確率最高 (D) 主要增加訓練次數,即使訓練資料標註錯誤或類別分布不均也不需處理
42. 如圖所示,若初始值為 `i = 1`,每次輸出後執行 `i = i * 2`,則「輸出 i」會 被執行幾次? (A) ⌈n/2⌉ 次 (B) ⌈log₂ n⌉ 次 (C) ⌊log₂ n⌋ 次 (D) ⌊n/2⌋ 次
43. 下表為部分 OSI 網路模型與常見協定/概念的對應。關於 MAC 位址的敘述,下列何者最正確? (A) MAC 位址主要用於應用層,用來識別不同網站的網域名稱 (B) MAC 位址主要用於傳輸層,用來決定 TCP 或 UDP 的連線方式 (C) MAC 位址主要作用於資料連結層,用來識別區域網路中的網路介面 (D) MAC 位址主要作用於實體層,用來決定網路線的電壓與訊號頻率
44. 班級名單已依學號由小到大排序,若要更有效率地找出某一學號是否存在, 下列何者最適切? (A) 循序搜尋 (B) 二元搜尋 (C) 泡沫排序 (D) 線性回歸
45. 關於計算機系統中用於表示浮點數的 IEEE 754 標準(單精確度 32-bit), 下列敘述何者正確? (A) 包含符號位元(Sign)1-bit、指數部份(Exponent)8-bit 以及小數/尾 數部份(Fraction/Mantissa)23-bit。 (B) 浮點數表示法能精確無誤地儲存所有的實數,不會產生任何捨入誤差 (Rounding error)。 (C) 指數部份(Exponent)採用二的補數(Two's complement)來表示正負 號。 (D) 單精確度浮點數的範圍與精確度皆大於雙精確度(64-bit)浮點數。
46. 關於 AI Agent 的技能擴充與「漸進式披露(Progressive Disclosure)」設計 機制,下列敘述何者最為正確? (A) 系統會在啟動時,將所有數千種工具的完整操作手冊一次性載入 LLM 的上下文窗口中,以利快速執行。 (B) Agent 僅依賴 LLM 原生的內部知識庫進行操作,無法動態調用外部腳 本或 API。 (C) 系統平時僅提供輕量級的技能目錄(如 YAML Metadata)供 LLM 建 立路由,當確認確實需要該技能時,才動態載入完整的執行規範(如 SKILL.md),以避免上下文 Token 過載。 (D) 當 Agent 執行工具發生錯誤時,系統會立刻關閉並要求人類工程師手 動重寫底層原始碼,不具備自我修正(Self-Healing)能力。
47. 針對大型語言模型(LLM)或 AI Agent 常遇到的「上下文窗口(Context Window)限制」與 Token 成本問題,下列解決方案的敘述何者錯誤? (A) 提示詞壓縮(Prompt Compression):透過演算法自動過濾輸入文本中 的冗餘字詞或停用詞,在不大幅流失語意下,增加視窗內可容納的有效 資訊量。 (B) 檢索增強生成(RAG):將外部長文本切割並向量化,提問時僅檢索最 相關的段落動態加入上下文,避免一次塞入全文。 (C) 即時權重更新(Real-time Weight Overwriting):在每次對話推論 (Inference)當下,即時執行反向傳播,將長篇上下文直接寫入模型權 重中,藉此徹底釋放視窗空間。 (D) 漸進式披露(Progressive Disclosure):系統預設僅載入眾多 AI 工具 的輕量描述(如 YAML 標籤),待判斷有呼叫需求時,才動態載入該 工具的完整程式碼。
48. 圖形資料結構在進階程式設計中佔有重要地位。關於圖形的深度優先搜尋 (DFS)及廣度優先搜尋(BFS)演算法,下列敘述何者錯誤? (A) 在某些特定結構(如分支度極高且深度較淺的樹)下,BFS 的記憶體 空間使用量可能會比 DFS 還要大。 (B) BFS 通常使用佇列(Queue)作為輔助資料結構來進行搜尋,而 DFS 則依賴堆疊(Stack)的後進先出特性進行搜尋。 (C) 在程式實作上,圖形最常見的兩種記憶體資料結構表示法為相鄰矩陣 (Adjacency Matrix)與相鄰串列(Adjacency List)。 (D) 由於 DFS 需要不斷回溯(Backtracking)尋找下一個未走訪的節點,因 此 DFS 程式極度不適合使用遞迴函數(Recursion)的方式來撰寫。
49. 關於演算法的時間複雜度(Time Complexity),在最差情況(Worst Case) 下,下列哪一種排序演算法的時間複雜度為 O(n log n)? (A) 泡沫排序(Bubble Sort) (B) 插入排序(Insertion Sort) (C) 選擇排序(Selection Sort) (D) 合併排序(Merge Sort)
50. 執行下列 C 語言程式碼,探討傳值呼叫(Call by Value)與傳址呼叫(Call by Address)的差異。請問程式最後印出的數值為何? (A) 5 13 (B) 10 13 (C) 10 10 (D) 5 10
 阿摩線上測驗
登入
阿摩線上測驗
登入
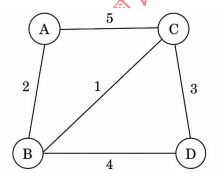 此圖的最小生成樹(Minimum Spanning Tree)權重總和為何? (A) 6 (B) 8 (C) 10 (D) 12
此圖的最小生成樹(Minimum Spanning Tree)權重總和為何? (A) 6 (B) 8 (C) 10 (D) 12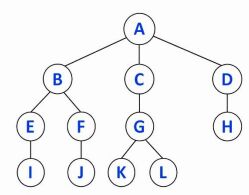 (A) A→B→E→F→I→J→C→G→K→L→D→H (B) A→B→E→I→F→J→C→G→K→L→D→H (C) A→B→C→D→E→F→G→H→I→J→K→L (D) I→J→K→L→E→F→G→H→B→C→D→A
(A) A→B→E→F→I→J→C→G→K→L→D→H (B) A→B→E→I→F→J→C→G→K→L→D→H (C) A→B→C→D→E→F→G→H→I→J→K→L (D) I→J→K→L→E→F→G→H→B→C→D→A
 (A) 顯示「舊網站」,連到 https://old.example.com (B) 顯示「前往學校網站」,連到 https://old.example.com (C) 顯示「舊網站」,連到 https://www.example.edu.tw (D) 顯示「前往學校網站」,連到 https://www.example.edu.tw
(A) 顯示「舊網站」,連到 https://old.example.com (B) 顯示「前往學校網站」,連到 https://old.example.com (C) 顯示「舊網站」,連到 https://www.example.edu.tw (D) 顯示「前往學校網站」,連到 https://www.example.edu.tw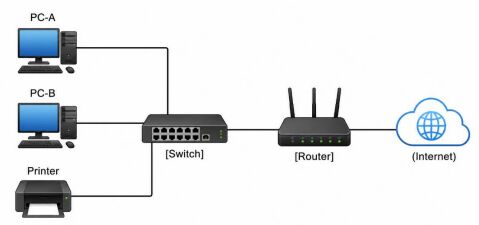 (A) Switch (B) Router (C) Printer (D) Browser
(A) Switch (B) Router (C) Printer (D) Browser (A) 增加多樣且正確標註的訓練資料,並保留獨立測試資料只用於最後評估 (B) 將測試資料加入訓練資料中,讓模型看過更多圖片後再回報測試準確率 (C) 只針對測試資料表現反覆調整模型參數,直到測試準確率最高 (D) 主要增加訓練次數,即使訓練資料標註錯誤或類別分布不均也不需處理
(A) 增加多樣且正確標註的訓練資料,並保留獨立測試資料只用於最後評估 (B) 將測試資料加入訓練資料中,讓模型看過更多圖片後再回報測試準確率 (C) 只針對測試資料表現反覆調整模型參數,直到測試準確率最高 (D) 主要增加訓練次數,即使訓練資料標註錯誤或類別分布不均也不需處理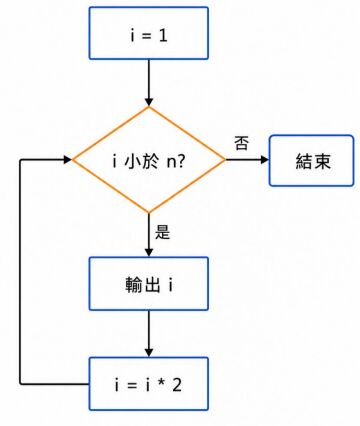 (A) ⌈n/2⌉ 次 (B) ⌈log₂ n⌉ 次 (C) ⌊log₂ n⌋ 次 (D) ⌊n/2⌋ 次
(A) ⌈n/2⌉ 次 (B) ⌈log₂ n⌉ 次 (C) ⌊log₂ n⌋ 次 (D) ⌊n/2⌋ 次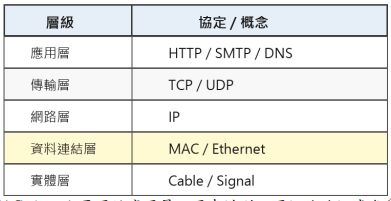 (A) MAC 位址主要用於應用層,用來識別不同網站的網域名稱 (B) MAC 位址主要用於傳輸層,用來決定 TCP 或 UDP 的連線方式 (C) MAC 位址主要作用於資料連結層,用來識別區域網路中的網路介面 (D) MAC 位址主要作用於實體層,用來決定網路線的電壓與訊號頻率
(A) MAC 位址主要用於應用層,用來識別不同網站的網域名稱 (B) MAC 位址主要用於傳輸層,用來決定 TCP 或 UDP 的連線方式 (C) MAC 位址主要作用於資料連結層,用來識別區域網路中的網路介面 (D) MAC 位址主要作用於實體層,用來決定網路線的電壓與訊號頻率 (A) 5 13 (B) 10 13 (C) 10 10 (D) 5 10
(A) 5 13 (B) 10 13 (C) 10 10 (D) 5 10